Mackerel SRE が実践する監視の育て方
これは Mackerel Advent Calendar 2023 の12/3分です.
昨日は ![]() id:rmatsuoka さんの Mackerel で開発中のマイクロサービスを OpenTelemetry のトレースを活用してパフォーマンス改善したでした. パフォーマンス改善でのトレーシング便利でいいですね.
id:rmatsuoka さんの Mackerel で開発中のマイクロサービスを OpenTelemetry のトレースを活用してパフォーマンス改善したでした. パフォーマンス改善でのトレーシング便利でいいですね.
今日は Mackerel の SRE が日頃どのように監視を育てているかについて書きます.
監視を育てる必要性とは
新しいシステムの構築や障害の再発防止など, 様々なことをきっかけに監視は構築されていきます.
監視は一度設定して終わりではなく, 運用しながらより適切な状態に近づけていく必要があります. もし不適切な監視ルールがあると, 不要なアラート通知なので何も行動しないということが常態化したり, 大量のアラート通知により見るべきアラートにたどり着きにくくなったりしてしまいます.
しかし, 適切な監視の設定はそう簡単ではありません. たとえば, ユーザーから見てサービスが期待される状態で提供されているかどうか監視する, のように監視の目的を考える必要があります. それはプロダクトや監視に対する知識や経験も重要になるでしょう. それに, 設定した時には適切な状態であっても, サービスの状況が変化し監視が期待と合わない状態になってしまっている場合もあります.
監視をよりよい状態に保つための監視設定の変更はしばしばあるもので, 監視をより適切な状態に近づけていくことを "監視を育てる" と呼んでいます.
はてなでは定期的にダッシュボードなどでシステムの状態を確認する機会*1を設けているチームが多く, そのコンテンツの1つとして発生したアラートの一覧を見ているところがあります. このように定期的なコミュニケーションの場を利用して監視を育てていくのも1つの手段です.
Mackerel の SRE としては, 新メンバーが自立していくための手段に監視の育成を利用しました.
取り組みの背景
ありがたいことに, 今年開発チームにはアプリケーションエンジニアと SRE で新しいメンバーがたくさん増えました. その新しく加わったメンバーにアラートや障害発生時の調査方法をどのように会得してもらうかについての悩みがありました.
かつての自分を思い出すと, アーキテクチャを把握したり, 先輩が調査している様子や過去の調査ログを見て教えていただいたりしてどのように調査していくのかを理解していったような記憶がうっすらとあります. このような調査方法は初回の導入としてはあってほしいものの, いざというときに素早く調べられるように, 予備動作なく動けるほどに慣れておきたいという思いは個人的にあります.
その前提にある監視ルールも同様に, その監視ルールは必要か, その監視ルールの設定は本当に適切なのかを考えるタイミングをどのように運用に組み込むかが悩みどころでした. 監視は設定して終わりではないため, 定期的に見直すための仕組みを作るのが目的です.
これまでの監視ルールの見直しは, 監視の一斉見直しや有志の行動によるものがほとんどで, 継続的とは言い難いものでした. 特に新規メンバーにとっては, 監視ルールの設定意図やシステムを十分に把握していないとアラート発生時に何を調査すべきかわからず, 監視ルールの変更を行うのもなかなかハードルがあるものでしょう.
このように, 監視ルールの形骸化の予防や現状のキャッチアップのためにも, 継続的な改善を設計するのがよいと考えています.
個人的な反省
監視を育てる体制を作ったきっかけはもう1つあります.
Mackerel である障害が起きたときに, アラートが発生していたのに誰も反応できていなかったというふりかえりがありました. これは, 監視ルールの意図を理解している人しかアラートの意味する状況が把握しづらい状態にあったのだと思っています.
つまり, チームメンバーにはアラートの通知内容だけでは発生しているサービス影響が伝わりにくい監視ルールの設定だったと言えます.*2.
また, 残念なことに, サービスの状態は正常なものの監視ルールに設定された閾値や監視対象のメトリックが適切でないためにアラートの誤報が上がることが慢性化した監視ルールもあり, アラート通知に対して緊急と捉えられない感覚になってしまっていたというのもあると思います.
この障害の再発防止策の1つとして, 緊急度が高いアラート通知*3には日頃からまずリアクションすることで, アラート通知は反応するべきものであるという認識を理解していくというものが上がりました.
しかし, このアクションを決めてから少し経って, アラートが発生しても結局何も変わらない自分にふと気づきました. 重要なアラート通知は把握している(と思っている*4 )ので, 重要ではない通知に何も反応せず気になった時に監視ルールを変更するだけの行動を意識では変えることができませんでした.
アラート通知に対して "いつもの(通知されるだけで対応の必要がないもの)" と呼ぶだけで何も行動しない監視ルールができてしまい, 監視の意図を把握しているひとだけが初動を取れるようなチームの状態であり, 加えて新規メンバーの割合の増加により知識の偏りが顕著になったと考えています.
チームのこの状況を改善するためにも, 監視とその運用体制を育てる施策の必要性を感じていました.
アラート当番を始めました
メンバーの育成と監視運用の仕組み化のために, 意識的に監視設定とアラートに向き合う場としてアラート当番という制度を作りました.
自分がアラート当番担当の期間に発生したアラートは, 緊急でないアラートも含めてすべてアラートが発生した原因を調査します. これはシステムや監視設定の把握と改善につなげるのが目的です *5 . 当番にすることによって, そのアラートは本当に必要だったのか, 監視ルールに改善点はないのかを特定の人に偏らせずに日常的に考える仕組みができました.
当番の交代時に自分の担当期間中に発生したアラートとその調査結果を共有することにしています. これで自分の知らなかった調査方法を知ることができたり, 調査に不足があれば必要な背景知識や他の調査方法のレクチャにつなげたりすることができます.
結果としては, 監視設定に今までより意識が向くようになったので, アラートの誤報が減りシステムの状態を改善することができました. アラート当番を始めた頃の調査ログを眺めてみると, 当時発生していた誤報や実は必要ではなかったアラートが, 今は必要な時にアラートがあがり対処方法がわかっている状態になりました.
アラート調査の責任者が明確になることで, 当番ではない期間は他のことに注力でき, 日頃からアラート通知や監視設定は適切なのか考える癖がつきました. また, システムへの理解も深まったと思います.
調査する上で, 監視やメトリックの不足が気になるようになり, mackerel-sql-metric-collector や cloudwatch-logs-aggregator, ラベル付きメトリック などを利用した可観測性の改善も見られました*6
アラート当番の副作用
一方で, アラート当番の負担は当番期間中に発生したアラートの量や内容に依存し, 時にはそれなりに重い負担となることもあります.
徐々に誤報が減り, 障害を未然に防ぐためのアラートが増えてより良い状態になりつつありますが, 今も負担がなくなったわけではありません. その負担からそのうち "いつもの" として当番交代時の共有が行われてしまう *7 可能性もあります.
ここに対しては, 現状の監視ルール設定が理想的ではないことが主な原因と考えています. 理想の監視を実現するには Mackerel に機能が不足していると感じていて, Mackerel にとって対応すべきテーマとして議題に上げているので今後の開発に期待ですね.
監視ルールの設定は自信を持って行えるときだけではありません. このメトリックでよいのか, この閾値でよいのか, この duration でよいのかなど迷うことも多いです. 当番により定期的に確認される仕組みがあることで, 監視を設定してからの経過観察も組み込まれているため, 監視ルールをとりあえず設定してみるハードルを下げることにもつながっていると考えています.
どのような監視設定にするか迷って設定されないことよりも, 間違っていても設定して改善していくことのほうが運用やシステムにとってメリットが大きいでしょう.
また, アラートの原因調査を日常にするとより効果的な調査方法が欲しくなり, いずれアラート当番の負荷軽減や障害対応の初速改善につながると考えています.
アラートの状況を SRE 以外にも共有する
アラート当番は SRE 中心の施策ですが, アラート当番で確認した内容は SRE 以外にも定期的に共有しています.
監視運用は SRE だけではなく開発チーム全体で考えるべきだと思っていて, アラート当番の内容を SRE に閉じた情報にしたくなかったためです. 具体的には, アラート当番のうち共有するトピックがあるものについて, このような情報をテキストで共有しています.
- なにが起きていたのか
- なぜそれがおきていたのか
- どのような対処を行ったのか
- 監視ルールをなぜそしてどのように変更したのか
監視を育てやすくする
監視を育てる仕組みを支えるものとして, IaC がとても役に立ちます.
Mackerel の監視ルールは Terraform Provider を利用してコード化することができます. コード化することでその監視ルールがなぜ必要なのかをテキストとして残し, 監視ルールの変更点についてプルリクエストで会話しそれも残すことができるというメリットがあります.
監視ルールを web コンソールで直接変更することは, 特に新メンバーには内容に妥当性があるか不安になることもあるものだと思うのですが, コードでレビューや会話を挟むことで, 安心して行えるものになったと考えています.
まとめ
監視を構築することと監視を育てることは別物であり, 監視を育てるには仕組みをつくることが重要です. また, 育てやすい状態にしておくとより実現しやすいのでおすすめです.
とはいえまだまだ道半ばなのでこれからも Mackerel の監視運用を改善していきます.
[PR] Mackerel Meetup #15 Tokyoを2023年12月19日(火)に開催します
「チームとコミュニティで監視を育てる」をテーマに、監視を育てるスタート地点でもあり、考え方でもある「SRE」の概念やその導入方法、具体的な実装について知ることのできるコンテンツを用意しています。Mackerelをお使いの方も、これから使い始めようという方も、明日から自分たちの監視やシステムを育てるヒントにしていただけたら幸いです。ぜひMackerelチームメンバーに会いに来てください!
詳細とご応募はこちらから! Mackerel Meetup #15 Tokyo #mackerelio - connpass
明日の Mackerel Advent Calendar 2023 の担当は ![]() id:issan883 さんです
id:issan883 さんです
*1:Performence Working Group, (略して PWG と呼びます)があります
*2:この情報伝達に限っては監視ルールのメモによる補足を進めています
*3:監視ルール名に緊急度を含めているので, アラートのタイトルでその緊急性がわかるようにしています
*4:じゃあなんで誰も反応しなかった状況が起きたのかって? なんと勘の鋭い... なぜなら会議中で見る余裕がなかったからね! (しっかりとは覚えていないけどその日のスケジュールを見るとそうなっていた)
*5:これとは別に, 発生したアラートのトリアージを行う役割も当番にはあるのですが, ここでは主題と逸れるためはぶきます
*6:アドベントカレンダー担当日のタイムリミットとこの記事の長さが気になってきたので, ほんとはちゃんと書きたかったけど急に雑な紹介になってしまった!
*7:これ自体は共通認識ができているという意味ではよいことなのですが, 何も行動しないことが常態化することは避けたいですね
Terraform Cloud に Insufficient rights って言われた
Terraform Cloud で API Token を使ったときに権限不足でうまくいかなかった
Error: Insufficient rights to generate a plan The provided credentials have insufficient rights to generate a plan. In order to generate plans, at least plan permissions on the workspace are required.
公式ドキュメントを見ると, Terraform Cloud には User, Team, Organization の3つの API Token があるらしい
https://www.terraform.io/docs/cloud/users-teams-organizations/users.html#api-tokens
User token
ユーザが持っている権限と同じ
terraform login したときは User Token が作られる
Team token
Terraform Cloud はチームベースに権限を管理していて, チームに対して organization と workspace への権限を定義できる
organization への権限はつけたりつけなかったりできる
workspace への権限管理のために設計されてるのと workspace 内だけで活動するのあれば organization の権限はなくてよい
workspace への権限としては Read/Plan/Write/Admin のプリセットの権限がある
plan と read と write が別れてるのが便利
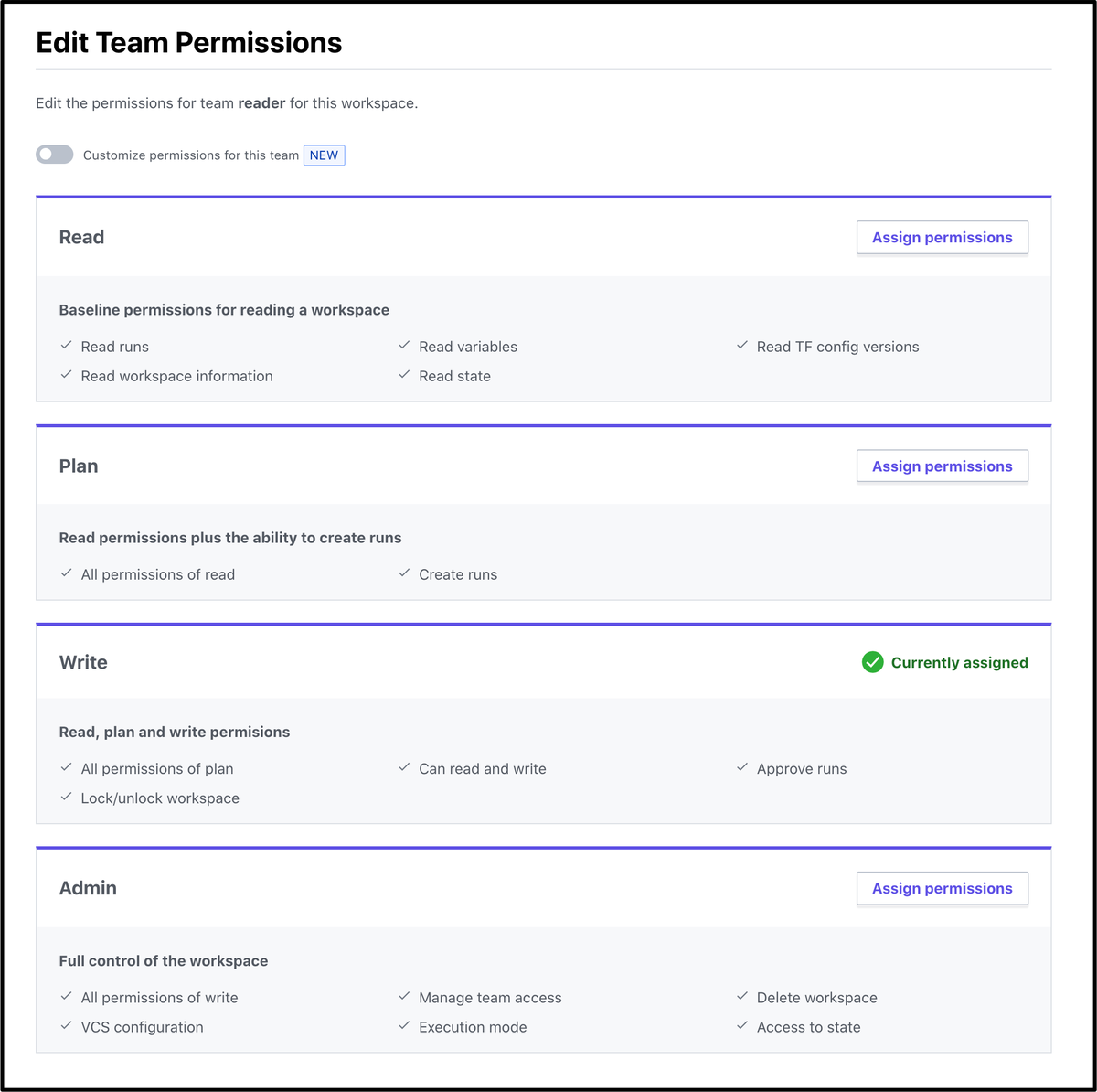
あとどうでもいいけど適当に作りすぎて reader に write 権限つけちゃってるのがおもしろい
新機能として細かく権限設定ができるようになってた
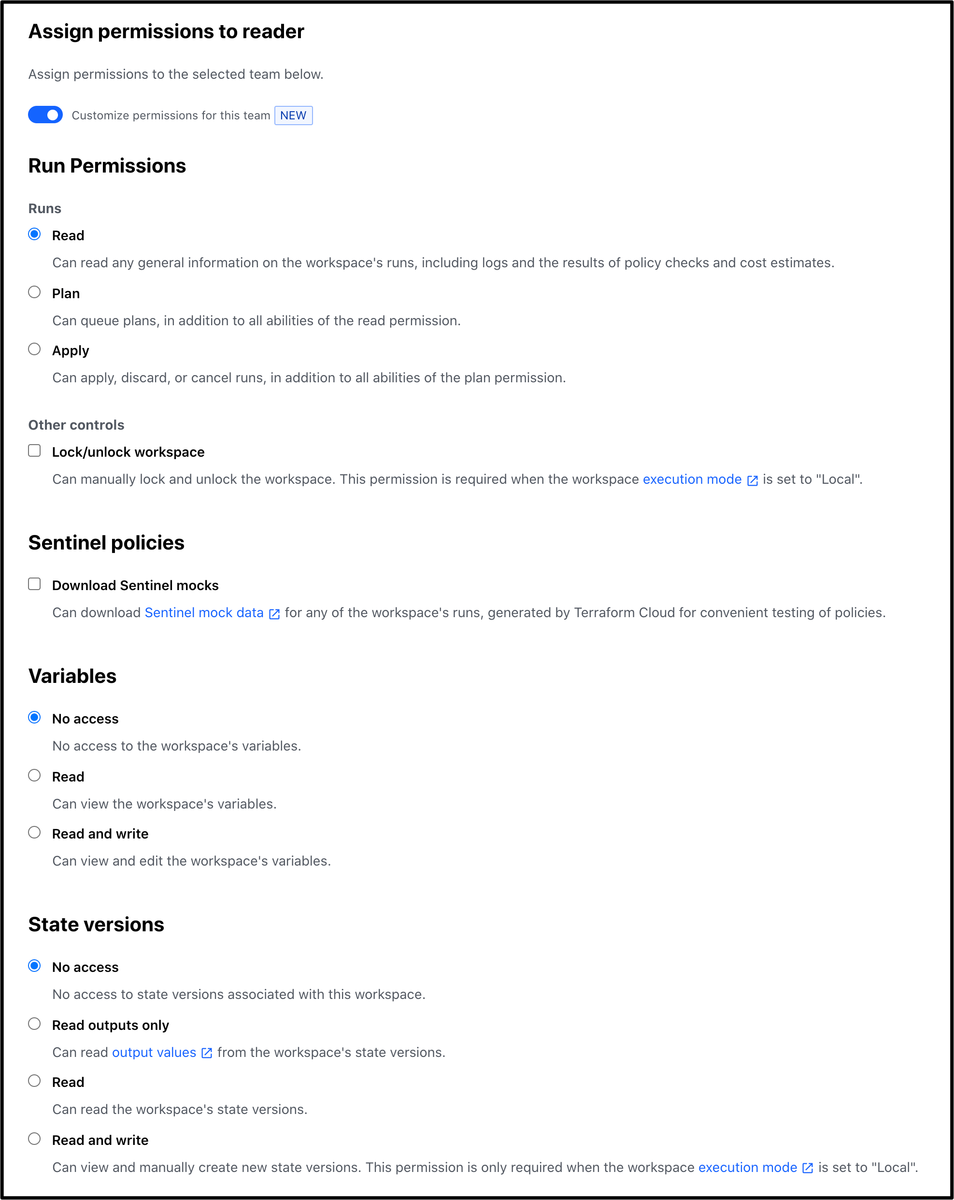
ここで言ってる workspace は Terraform Cloud の workspace のことで terraform workspace のことではない
あと Terraform Cloud で terraform workspace は使えない
難しいね...........
チームと同じ権限を持つAPI Tokenを作れるけど1チーム 1Token という制約がある
owners っていうデフォルトである強いチームと同じ権限をもたせることもできる
なので team token で実質 organization token になれるけど用途が違うのでメリットもなさそう
Organization token
organization レベルの設定ができる API Token を発行できて, チームや workspace の管理のために使われる
これも team token と同じで1チーム 1Token という制約がある
Terraform Cloud で workspace を作るまでを想定した token なので workspace への操作はできるけど plan とかはできない
ここまで読むとたしかに Organization で発行された Token は使えない気配しかなかった
workspace 1つずつに team を設定していくのがめんどうで organization で発行して使おうとしてたのがそもそも制約上NGだった....
それを管理するための organization token だけど...
organization はある程度大きな単位で作成して, workspace で分けていく想定で作られているのかな
API も Organization token を受け付けない
The organization token cannot perform plans and applies.
使えないぞってはっきり書いてある
権限管理めんどくさくて嫌になるけどこれくらいシンプルで用途を明示してくれてるのでやりやすくてよい
AWS LambdaでAWS SDK for Rubyはuploadする必要がなかった
ちょっとしくじってて実はうまくアップロードできてないのに
なぜかLambdaの実行に成功しててあれ?って思ったので
AWS LambdaでRubyを実行するときに
何のgemがすでに入っているのかが気になりました
思った以上にいっぱい入ってた
めっちゃ長いので超割愛するけどAWS SDK for Rubyは全部入ってそうな気配ある
aws-sdkも入っていたり、
たとえば aws-sdk-ecs は 1.59.0 なんだけど
これの最新のリリースは 1.59.0 - March 16, 2020 で最新に追従されている
bundlerやrdocも入っているのは嬉しいね
aws-eventstream 1.0.3 aws-partitions 1.285.0 aws-sdk 3.0.1 aws-sdk-accessanalyzer 1.3.0 ... aws-sdk-ecs 1.59.0 ... aws-sigv2 1.0.1 aws-sigv4 1.1.1 bigdecimal 1.3.4 bundler 2.1.2,2.1.4 cmath 1.0.0 csv 1.0.0 date 1.0.0 dbm 1.0.0 etc 1.0.0 fcntl 1.0.0 fiddle 1.0.0 fileutils 1.0.2 gdbm 2.0.0 io-console 0.4.6 ipaddr 1.2.0 jmespath 1.4.0 json 2.1.0,2.3.0 openssl 2.1.2 psych 3.0.2 rdoc 6.0.1.1 rubygems-update 3.1.2 scanf 1.0.0 sdbm 1.0.0 stringio 0.0.1 strscan 1.0.0 webrick 1.4.2 zlib 1.0.0
Mackerelを起点にAmazon EventBridgeを経由してホストを削除する
MackerelのAmazon EventBridge対応が出ました
AWS Black Belt でも紹介されてて、EventBridgeまわりがわかりやすく説明されています
物理で光るのはテンションあがってとても良い!
わたしもこれでなにかおもしろいことしたいな〜って思ってたけどネタが思いついてなくて、
そんなときにチームの人がふと
"MackerelでホストステータスをPower Offにしたらホスト退役するとか、できるか知らんけどw"
って言ってて、その考え方が自分になくておもしろいなと思って作ってみました
普段AWSでホストが起動すると、
MackerelエージェントやAWSインテグレーションでMackerelに連携されて、
ホスト退役すると自動でMackerelから消えて... とAWS起点で考えてたのですが
Mackerelを起点にホストを管理するというのが逆転的でこれいいじゃんって思いました
つくる
公式ドキュメントとして手順が丁寧に書いてあるのでそのままぽちぽち設定します
よくわからなかったのがドキュメントではあまり触れられていない Event matching pattern のところで、
ちゃんと選択してSaveしてもなぜかAllで保存されちゃいました

これはAWSでの設定なのですが、なんでこうなるんだろう🤔
Allでもサービス指定しても(Allで保存されるけど)問題なく動きます
ぽちぽちってするだけでMackerelのイベントとAWSのリソースが連携できるのはめっちゃ楽でいいですね
できた
とっっっても突貫でつくりました
MackerelでECS FargateのタスクのホストステータスをPower Offにすると
Mackerel -> EventBridge -> Lambda -> ECS とリクエストし、
そのタスクがストップされます
Max, Desired CountやAuto Scalingを変更するわけではないので、
たとえばDesired Countが2になっていて、1つをPower Offにすると、
一時的に1タスクになり、そのうち2つ目が起動してきます
ほんとうはこれは3つ目を立ててからStopするほうが親切ではあるのですが
勢いだけで作ってしまったのでタスクは即Stopしにいってしまいます😅
EventBridgeのTargetの設定画面の

これをぽちぽちするよりLambda書いたほうが簡単そうって感じたのでLambdaにしました
ブラウザ得意になりたい
なんでFargateなのかというと、そこに動いているクラスターがあったからで、
そこに対する理由や考察は全く無いです
作ってみて
今回、MackerelでFargateで稼働しているタスクの様子を見て
違和感のあるやつはPower Offすると入れ替わるっていうシナリオを考えたのですが、
実際Fargateでそんなことあるのか?🤔 という感じです
Mackerelのグラフがきれいなので、
そのグラフからそのままアクション取れたらスムーズでいいな〜
でもこのHostなんか調子悪そうだから入れ替えたいねっていう話だと
今更だけどECSよりEC2のほうが向いていそう
あとMackerelが本来用意しているホストステータスのPower off機能に別の機能を付け加えてしまったので、
本来の用途で使おうと思ったときにびっくりしてしまうかもね
思想も実装もガバガバなくらい動く楽しさ重視で作ってみたからしょうがないね!
Mackerelのどんなイベントが起こったら何をするかという定形のアクションがあったとき、
それをコード化できるっていう部分がとても好き
SlackでMackerelのアラートの様子を見る
これは Mackerel Advent Calendar 2019 - Qiita の20日目の記事です
アドベントカレンダーに登録したら部屋がきれいになった話にならなくてよかったです
こんなことありませんか?
日中ふと見かけたアラート、作業をして発生させたアラート...
あいつらちゃんと片付けたっけ?って気持ちになって寝付けなくなったりしませんか?

ちなみにわたしはアラートではあまりないですけど、
乾燥機つけたっけ・・・というのはよく気になって起きて確認しに行ってます
そういえばAWSでこんなリリースがありました
AWS ChatbotがSlackから実行できるようになりました!
SlackからLambdaが起動できるので、
いろんなことができるようになって夢が広がりますね
SlackからMackerelのアラートを見れるようにしよう!
アラートが上がったタイミングではなく、
任意のタイミングでSlackで見れたら便利かもという気持ちになって作りました
サービス名を指定して、
Slack -> Chatbot -> Lambda -> Mackerel とリクエストして、
結果をSlackにPostします
この解説こそ図示するべきかと考えたのですが、
AWS Chatbotのアイコンは配布されていませんでした
まだベータ版ってこともあるのかな
作り方
まずAWS Chatbotの設定をしていきます

他の選択肢としてはAmazon Chimeがあります

Slackに飛ばされるので設定します

あとはLambdaの中身を実装してデプロイし、Slackから実行するだけです
できた
サービス名を指定して、
そのサービスでOpenなアラートを見れるようにしました
https://github.com/heleeen/alert_checker

アラートがないときはこんな感じです
平和なときはお寿司を食べようっていう気持ちです

頑張ったところはSlackにPostするためのJson作りです
できあがるまでの頑張り
サービスはアラートから取得できない
アラートのレスポンスにサービスは含まれていないので、
アラートからモニターIDを取りそれでモニターを引き... みたいなことをしています
ただ、式監視だけはモニターにもロールの設定がなく
サービスの特定ができなかったのでアラートがあっても取得できません...
式にサービス名があるかどうかを grep するくらいしか思いつきませんでした...(やってないですが...)
AWSコンソールでは実行できるのになぜかSlackから実行できない
@aws lambda invoke --payload {"service": "serviceName"} --function-name alert_checker --region ap-northeast-1というように実行するのですが、
このPayload部分が厄介で、Macの場合、
Slackにコピペで貼り付けたり入力しようとすると
ダブルクオテーションが変換されてしまいエラーしました

これはシステム環境設定で回避できますが、
他でもダブルクオテーションの向きが修正されなくなるので悩ましいですね
IAMロールの編集はIAMのコンソールから
何気なく↓を実行しようとしたところ、ReadOnlyが必要でした
@aws lambda list-functions ...
ただ、ChatbotのコンソールからIAMロールを編集できません
IAMのコンソールに移動するか、新しく作る必要があります
IAMにしゅっとつけられる体験を最初にしてしまっていたので、
ああ...IAMのコンソール出てくるんだ... という気持ちになりました
コマンドが長い
セヤネン
お布団から寝ぼけたまま打つのはきついので
Slackのほうのbotとかにいい感じにさせたほうがよさそう
Alexa, XXXのアラートを確認して!っていうのも考えたのですが、
楽しそうだけどデバッグ大変そうで諦めました...
楽しそうではあるんだけど...
なぜかLambdaコンソールでの実行は成功するのにSlackからだと返事がない
なんでだろうね
困って↓を入れました
sleep 10
https://github.com/heleeen/alert_checker/blob/master/function/lib/slack.rb#L17
クッ....なぜだ.....
APIやGemが公開されているとこういう連携が楽でいじりがいがあって楽しくていいですね
もっといじりたい
あと乾燥機つけたかどうかもSlackでわかる日がきて欲しい